
證券時報網
吳志
2025-11-19 20:49


美東時間11月18日早間,互聯網基礎設施服務商Cloudflare發生大規模宕機,依賴其網絡和安全服務的眾多網站隨即受到波及,大量全球知名互聯網服務出現訪問速度下降、頁面報錯甚至完全無法訪問的狀況,影響范圍涵蓋社交網絡、人工智能服務、電商、云服務乃至部分公共交通系統。
當天清晨5點20分左右,Cloudflare監測到網絡中出現異常流量激增。隨后,負責處理廣泛服務流量的軟件系統接連出現錯誤,導致大量網絡請求無法正常響應。DownDetector數據顯示,X、Spotify、OpenAI、亞馬遜云服務AWS、Shopify、Truth Social等多項服務出現大面積故障,甚至連DownDetector自身也因依賴Cloudflare服務而短暫無法訪問。
故障發生后不到兩小時,Cloudflare表示,已經開始調查問題。上午7點30分左右,公司稱部分服務正在恢復,但用戶仍可能遇到訪問延遲或錯誤。進入8點,公司確認找到了故障源頭,修復正在推進。9點42分至9點57分,Cloudflare發布最新狀態更新,宣布核心問題已經解決,大量受影響網站陸續恢復,但部分用戶訪問管理后臺依然可能遭遇不穩定。
本次事故的根本原因來自Cloudflare內部的一套用于識別和阻斷惡意機器人流量的自動生成配置文件。該配置文件在例行升級后規模意外變大,遠超系統預期,最終觸發負責整體流量處理的軟件組件持續崩潰。
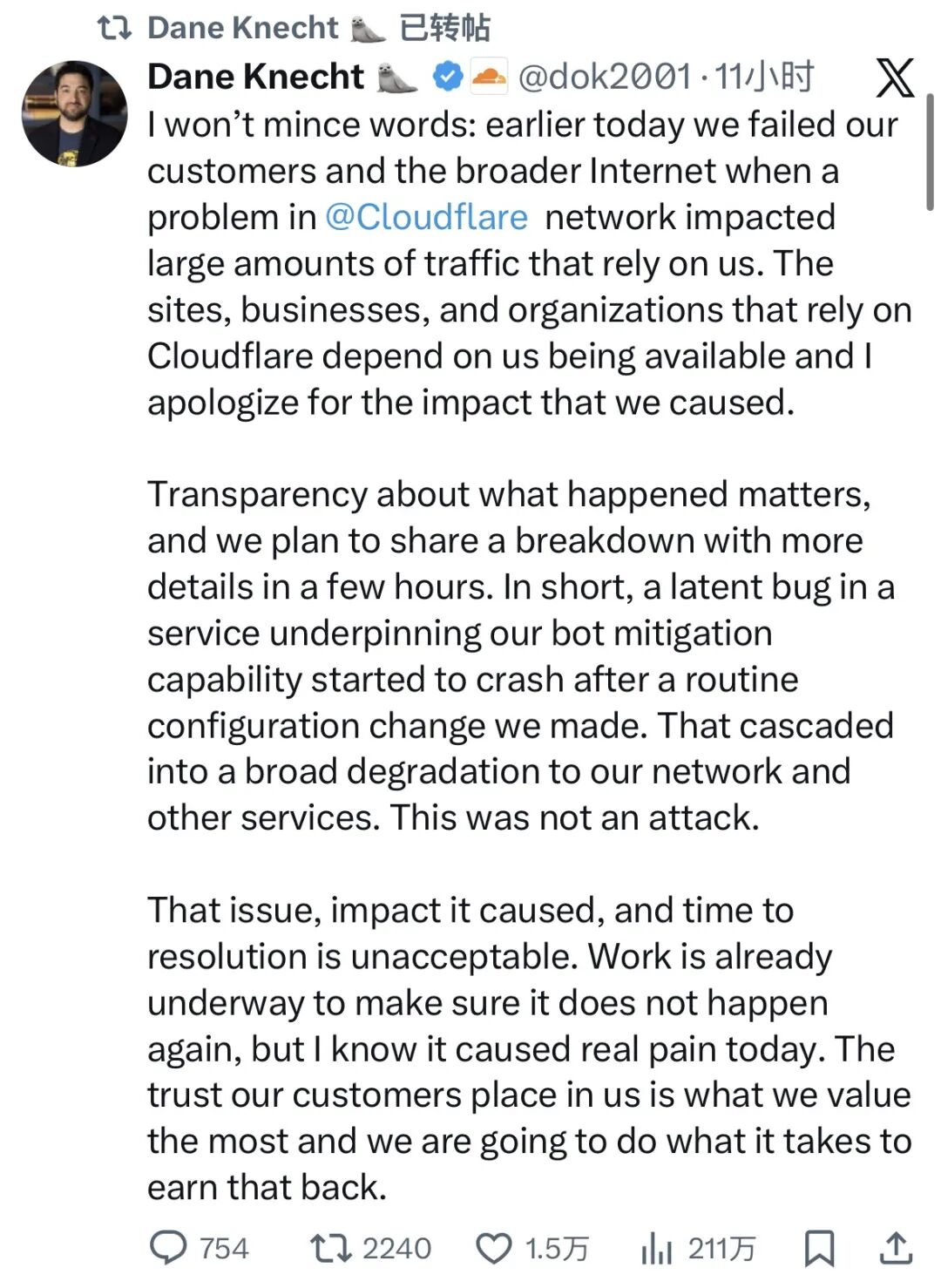
Cloudflare首席技術官戴恩·克內希特(Dane Knecht)在X上公開致歉,“今天早些時候,Cloudflare網絡出現問題,影響了大量依賴我們的流量,我們辜負了我們的客戶和整個互聯網。”
Cloudflare CTO社交媒體發言
戴恩·克內希特同時強調,沒有證據顯示此次事件源自攻擊或惡意行為。
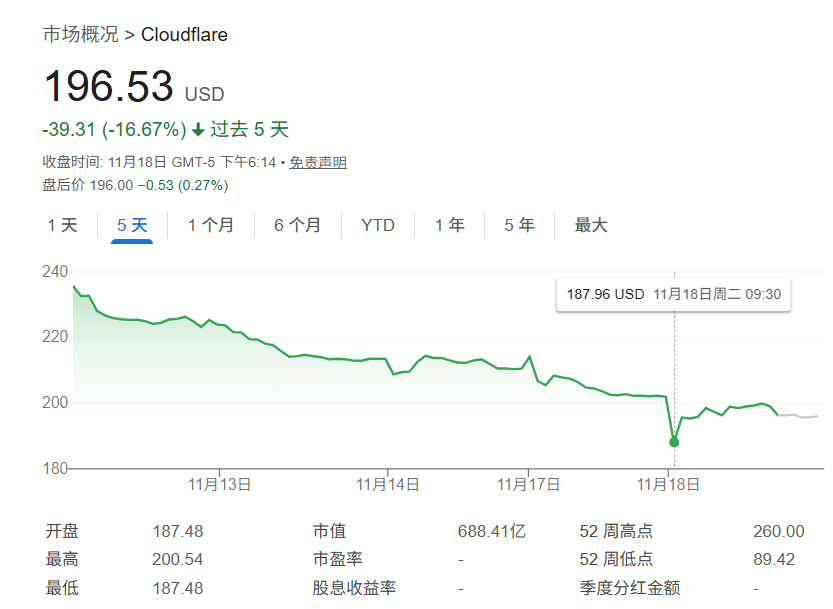
作為全球處理約20%互聯網流量的重要基礎設施提供方,Cloudflare的故障導致股價在事件發生后短時間內下跌超過2%,市場情緒受到波動。
Cloudflare方面表示,將繼續監控修復情況,并采取措施避免類似問題重演。
Cloudflare股價
網絡連接監測組織NetBlocks總監Alp Toker認為,本次事件展示了Cloudflare基礎設施在出現災難性故障時對互聯網帶來的系統性沖擊。近年來,越來越多網站為提升安全性與穩定性,將流量托管或保護交由Cloudflare,但這種集中化也使其成為互聯網“最大的單點故障之一”。
ESET全球網絡安全顧問杰克·摩爾(Jake Moore)也指出,由于可選擇的托管平臺有限,大量企業不得不嚴重依賴Cloudflare、AWS或微軟等大型服務商,而集中度過高意味著任何一次重大故障都可能引發連鎖反應。
此次宕機不僅影響了商用網站,政府部門也在密切關注事件進展。紐約市應急管理部門表示,已持續監測該事件導致的公共服務運行情況,目前尚未發現重大資源調度壓力。
目前,OpenAI、Spotify、Shopify、Canva、Zoom以及部分公共交通服務均已確認因“第三方服務問題”受到影響,并陸續恢復。
不可忽視的是,這已經是全球互聯網基礎服務近期發生的又一次大規模事故。就在一個月前,亞馬遜AWS出現持續故障,導致超過一千個網站和在線應用數小時癱瘓。微軟Azure及365服務也曾發生全球性宕機。今年7月,美國網絡安全服務提供商CrowdStrike的一次軟件升級錯誤則造成全球范圍藍屏事故,機場停航、銀行受阻、醫院手術延期,影響持續多日。






